
(一)模型介绍
1.关键词提取
(1)自动切词:默认在全部文本中,采用TF-IDF算法提取出指定数量的重要关键词
(2) 自定义部分关键词:可自定义关键词,然后结合使用TF-IDF算法提取出指定数量的重要关键词。
(3) 完全自定义关键词:按照用户输入的关键词进行统计。
2. 词关系
(1)Jaccard系数(交集与并集的比值),即词语共同出现的频次与各自单独出现频次和之比。系数值越大,关系越强,系数值越小,关系越弱。
(2)数值标准化,为方便系数结果的观察及解读,采用数值标准化方法,标准化后数据区间(0.1,1)。
3. 统计指标
(1)节点度(Node Degree):节点度是指和该节点相关联的边的条数,又称关联度。
(2)度数中心性(Degree Centrality):节点与其他节点直接连接的总量,由最大可能度归一化而来,由于存在循环,该值可能大于1。在有向图中依据连接的方向,分点入中心度(或入度,in-degree)和点出中心度(或出度,out-degree)。衡量了节点单独的价值。
(3)接近中心性(Closeness Centrality),即节点到其他所有节点距离的总和的倒数,由最小距离归一化而来,体现节点与其他节点的近邻程度,接近中心性值越大,表示节点能够更快到达其他节点,衡量了节点的网络价值。
(4)中间中心性(Betweenness Centrality), 即经过节点的最短路径的数量,由最大可能值归一化而来,衡量了节点在其他节点之间的调节能力。
(5)共现关系(Co-occurrence),两个节点共同出现的次数。
(6)网络密度(Network Density),用于刻画网络中节点间相互连边的密集程度,在社交网络中常用来测量社交关系的密集程度以及演化趋势。
4. 词分类(社区划分)
对网络关系图进行社区划分, 同一类(社区)的节点连接密集,不同类(社区)间的节点连接稀疏。 依据Vincent D.Blondel 等人于2008提出,基于modularity optimization的heuristic方法而來。详见:
https://en.wikipedia.org/wiki/Modularity_(networks)
https://perso.crans.org/aynaud/communities/api.html#module-community
(二)研发依据
[1] 王功辉,浏卫江.基于关键词共现的文本信息分析方法及应用研究–以信用评价为例[EB/OL].中国科技论文在线.2010.
[2] 韩普,王东波,王子敏.词汇相似度计算和相似词挖掘研究进展[J].情报科学.2016,34(9):161-165.
[3] Aric Hagberg,Dan Schult, Pieter Swart.NetworkX Reference.2018,1,22:171-174.
(三)算法说明
TF-IDF算法:
如判断一个词在一篇文章中是否重要,一个容易想到的衡量指标就是词频,重要的词往往会在文章中多次出现。但另一方面,不是出现次数多的词就一定重要,因为有些词在各种文章中都频繁出现,那它的重要性肯定不如那些只在某篇文章中频繁出现的词的重要性强。从统计学的角度,就是给予那些不常见的词以较大的权重,而减少常见词的权重。IDF(逆文文件频率)就是这个权重,TF则指的是词频。
Jaccard系数:
用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,相似度越高。
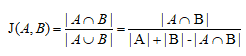
(四)约束与限制
- 默认以文章为词语共现的基本计算单位,当确定关键词之后,需要在各篇文章中计算任意两两关键词组合的共现次数。于是,关键词组合方式的数量、文章总数量决定了模型计算时间的长短,由于循环迭代次数很多,一般耗时会比较久,对计算资源要求较高。
- 在指定关键词情况下,由于会将不包含指定关键词的所有文本过滤掉,当所有文本均不包含上述关键词的时候,就会过滤掉全部文本,即计算结果为空。
- 权衡计算精度、效率与资源之间的关系,当计算数据篇数大于10000篇或字符总数大于10000000时,采用随机抽样方式来提取关键词,后续计算依旧是全量计算。
- 当指定自定义关键词时,由于存在繁简体格式,默认会自动扩展成包含繁简体,提取关键词时候,数量可能会多于指定的关键词数量。
- 计算耗时受多种因素限制(如:网络稳定性、数据量、复杂度、操作准确性等),查看计算结果需刷新原始页面,多数情况耗时5-10分钟,若30分钟内未看到计算结果,请反馈给客服予以跟进。
