
在大数据的时代下,做分析的数据量与以前相比,是不可同日而语。算法编码的出现,不免让许多研究者看到了希望。因为算法编码的优点是极为高效,可以在很短时间内完成数据分析。算法编码是指采用算法或计算机挖掘数据内部规则,来得出数据编码结果的方式[1]。它可以由研究人员设定编码规则,让计算机代为执行编码过程。因此,面对庞大的数据量,想要处理客观性文本表达时,算法机器人的介入成为一种实现高效的必然之选。
什么是机器法编码?
机器编码,实际上是借助大数据技术进行算法编码,但这个过程中,依旧有人工的介入,只是人工介入程度较人工编码少。大数据算法编码通常是通过人工编码作为基准来实现的。这个过程基于这样的一个假设:人类对文本的理解仍然优于机器,如果训练正确,人类将对文本做出最正确有效的分类[2]。所以有人工设定高质量的编码规则,加之良好的编码员培训,可确保在传统的人工内容分析中的数据质量水平,也被视作内容分析的标准做法。
说到这里,不难发现,实际上算法编码的准确性依然依赖于人工介入的部分,尤其是人工对算法的设定规则,这直接决定了数据的质量。而算法编码只是由算法机器人执行,指引机器对文本进行关键词的自动化标注和自动化填答选项,以完成自动编码,借此提高编码效率。
算法编码也需要考虑编码质量的问题?
学者Song等人[3]指出,如果不能确保用于验证的人工编码的质量,则研究人员就自动化程序的性能得出错误结论的风险要大得多。可见,在使用算法编码时,信度测试是十分必要的!
但在不少研究中,算法编码的信度评估却被忽略。学者Song等人[3]表示,他们分析了73项使用文本自动分析的研究,当中有37项报告使用人工编码进行验证,但只有14项充分报告了人工编码数据的质量,有23项完全没有报告任何编码员间的信度。
可见,在目前文本自动分析的应用中,仍存在着完全不考虑信度,或未严肃对待信度的错误认知。但实际上,在使用算法编码做文本自动分析时,首先需要评估的信度,就是编码员间信度,因为自动文本分析的编码效度,实际上是依赖于研究人员对编码规则的定义水平[4],而它也奠定了机器学习的数据质量水平。
但确保了人工编码的信度后,并非就完成了对算法机器人的评估。而是应该再进一步,评估人工定义的规则,在算法编码中实现的情况。
可见,在使用算法编码的正确操作流程应该是:先确保人工介入部分,即人工制定之规则的信度,再将其应用于算法编码中,并比较算法编码与人工编码的一致性,在两者达到一致性后,才可采用算法编码结果作为解读依据。
DiVoMiner®上的信度测试功能,除了能实现对编码员间信度的评估外,同样可以评估算法机器人的信度。
评估机器人算法的操作流程
下面详细给大家介绍一下具体的操作流程:
第一步:人工设定算法的规则
【类目管理】-【新建问题】。
添加【选项】及其对应的【关键字】,即可设定算法规则。
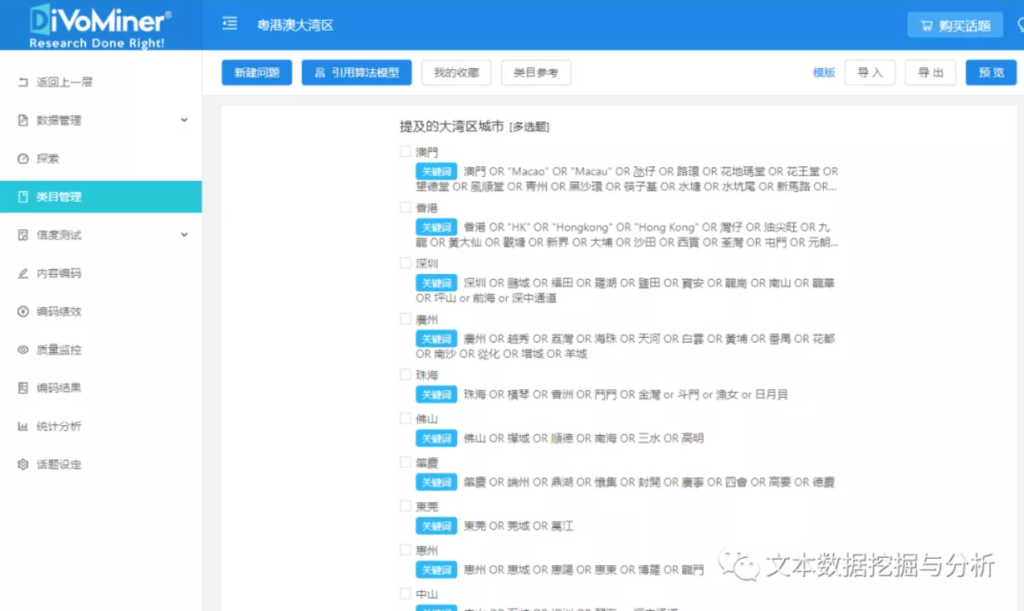
第二步:建立测试库
【数据管理】-【编码库】-【随机导入到测试库】,即可完成测试库的建立。也可以选中某一条数据,点击数据右侧的【测试库】单独导入到测试库。进入到【测试库】查看已导入用以进行信度测试的数据。
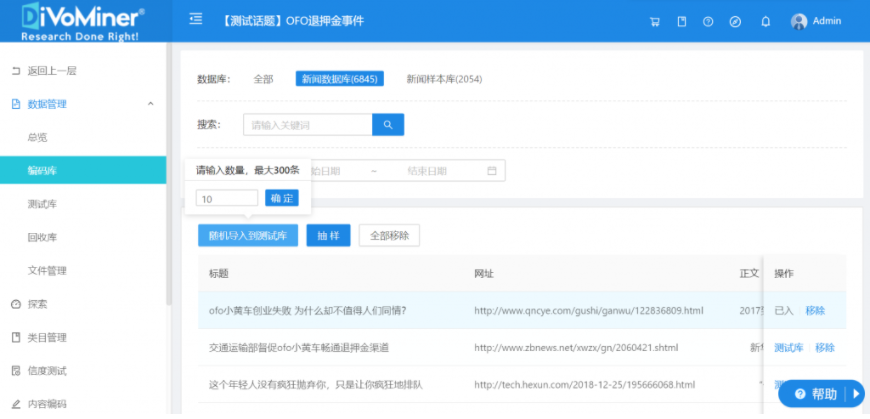
第三步:做测试编码
所有编码员进入到【信度测试】-【编码测试】中,阅读文本,填写页面右侧的编码簿,点击【保存】完成编码。
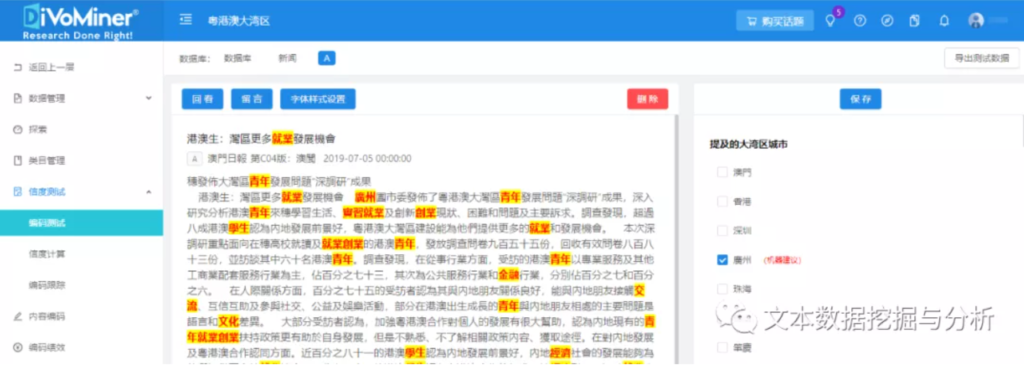
第四步:评估信度
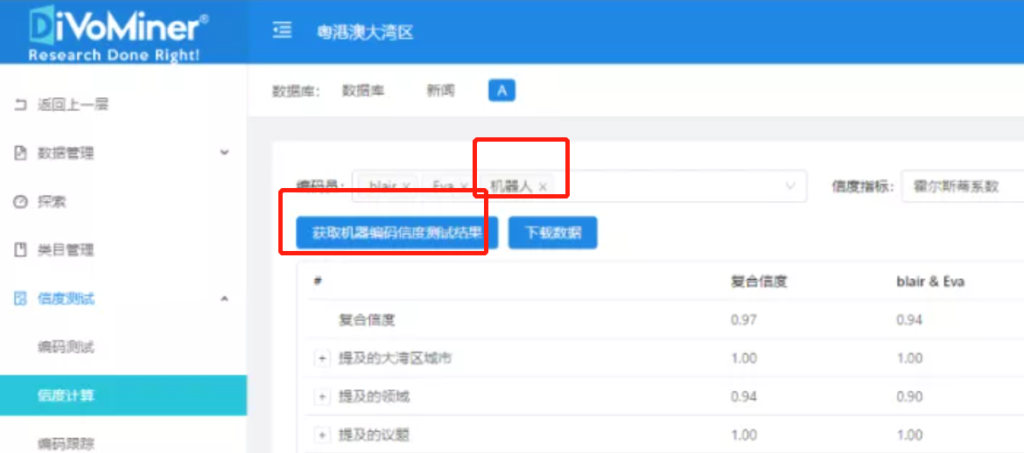
在完成编码后,信度结果即可实时查看!待所有编码员完成测试编码后,在【信度计算】中,选择编码员和信度指标,点击【计算】,得到编码员间信度结果。
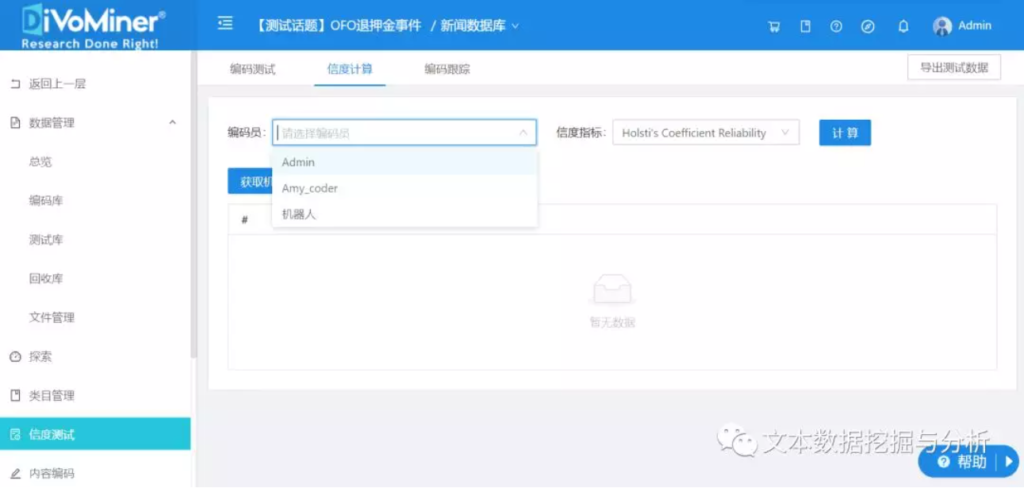
其次,我们选择编码员、机器人和信度指标,点击【获取机器编码信度测试结果】,再点击【计算】,对比人机一致性,若信度达标,证明算法编码结果可接受,则可让算法机器人分析文本大数据。
小提示
在利用算法机器人完成编码后,研究者也可以在【质量监控】中,查看或进一步修正机器编码的结果哦。
[1] Zmatchamith, R., & Lewis, S. C. (2015). Content analysis and the algorithmic coder: What computational social science means for traditional modes of media analysis. The ANNALS of the American Academy of Political and Social Science, 659(1), 307-318.
[2] Lowe, W., & Benoit, K. (2013). Validating estimates of latent traits from textual data using human judmatchgment as a benchmark. Political analysis, 21(3), 298-313.
[3] Song, H., Tolochko, P., Eberl, J. M., Eisele, O., Greussing, E., Heidenreich, T., Lind, F., Galyga, S., & Boomgaarden, H. G. (2020). In validations we trust? The impact of imperfect human annotations as a gold standard on the quality of validation of automated content analysis. Political Communication, 37(4), 550-572.
[4] Riffe, D., Lacy, S., Fico, F., & Watson, B. (2019). Analyzing media messages: Using quantitative content analysis in research. Routledge.
[5] 程萧潇, 金兼斌, 张荣显, & 赵莹. (2020). 抗疫背景下中医媒介形象之变化. 西安交通大学学报:社会科学版(4), 61-70.
[6] Chang, A., Schulz, P. J., & Wenghin Cheong, A. (2020). Online newspaper framing of non-communicable diseases: comparison of Mainland China, Taiwan, Hong Kong and Macao. International journal of environmental research and public health, 17(15), 5593.
