
文本情感分析(sentiment analysis)的目的在于了解作者在特定文本中的情感态度,这些态度反映了作者在撰写该文本时的个人情感,或是意图经由该文本向读者所传达的情感。自动化的文本情感分析,是指结合自然语言处理(Natural Language Processing)、文本挖掘(Text Mining),以及计算机语言等领域的技术方法,来提取文本中的主观情感信息。平台所提供的自动化情感分析模型由DiVoMiner®团队独家研发,可自动识别和分析文本中表达的情感或态度倾向(标记为正面、负面或中立),该项技术正在申请专利。
基于团队对算法模型的不断升级和丰富的语料支持,经测试,特定类别语料情感分析Accuracy(准确性或准确率)达到0.7~0.9(业界接受范围内)。测试结果如下,建议用户根据实际研究情况确定模型适用性。
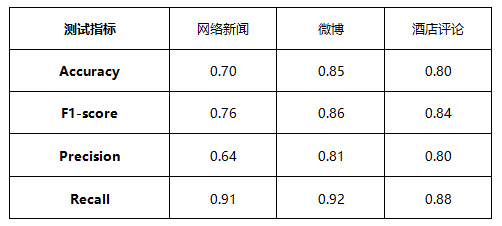
提示:以上测试结果均基于内部数据测试集,而“准度”是建立在特定的测试集的基础之上,可通过通用评价指标(如:Accuracy、F1-score、Precision、Recall)给出的量化值进行判断。受测试集的限制,“准度”范围会产生波动,目前并无严格的业界标准。
指标说明:
- Accuracy(准确性或准确率):预测正确的样本数占总样本数的比例。
- F1-score(F1值):Precision和Recall的调和平均值。
- Precision(精确率、精度或查准率):预测正确的数据占预测数据的比例。
- Recall(召回率、查全率):预测正确的数据占实际数据的比例。
参考文献:
【1】Powers, David M W (2011). “Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation” (PDF). Journal of Machine Learning Technologies. 2 (1): 37–63.
【2】周志华, 杨强. 机器学习及其应用2011[M]:清华大学出版社,2011
