
在内容分析法(Content Analysis)中,内容编码(Coding)是关键步骤,分类思维是核心要义。操作程序是把多模态数据(文本、图片、音频、视频)转化为量化数据,后续进行统计分析处理。在很多研究实践中,也常采用量化、质化数据结合解读的方式来达到研究目的。
传统内容分析法中,内容编码是人工针对文本进行逐一阅读,填答编码表,做完所有的内容编码后,将编码簿中的数据汇总整理,进行统计分析和可视化效果呈现。这个过程非常耗时耗力(小编经常听到用户朋友们抱怨,做人工编码做得头晕眼花,简直要哇的一声哭出来)。
为了解决传统内容分析法编码操作繁琐的问题,DiVoMiner平台的研发团队想了不少办法,最终确定采用结合了传统内容分析法、大数据技术、人工智能的创新执行方案,在内容编码的方式上,提供了人工编码(可机器、AI辅助)、机器编码和AI编码三种方式。
那么,有小伙伴表示疑惑,同样是做内容编码,这三种方式到底有什么差别呢?应该如何做选择呢?想要弄明白这个问题,就得先了解这两者的执行差异和各自的优劣势。
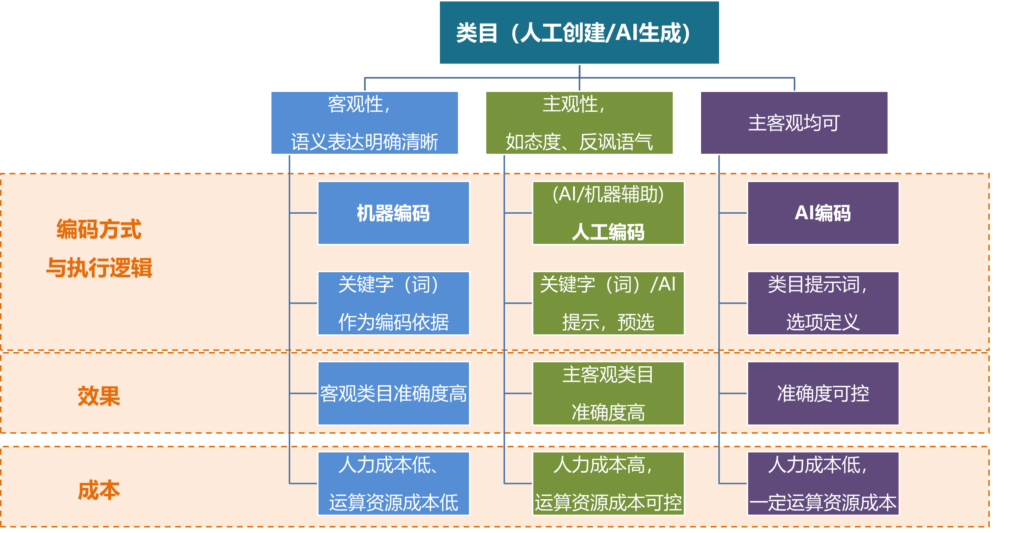
先上结论,选择何种编码方式,关键看类目属性和投入资源的水平!
客观类目题目推荐机器编码,高效可靠,成本低;
主观类目题目用(机器辅助)人工编码,准确性高,消耗人力,相对费时费力;
AI编码则是兼顾客观和主观题目,效率高,速度快,需要投入一定的运算资源。
(见下表总结↓↓↓)
- 什么情况下选择机器编码?
客观性的题目,如机构、人名、事件等,表达清晰,可以用语义概括,这种题目极为适合做机器编码,效率极高,非常省心省事,搭配系统机器人的信度检验,编码结果放入论文、发表高水平期刊无压力!
- 什么情况下选择(机器辅助)人工编码?
如果是主观性类目题目,以目前的科技手段难以做出准确判断,如指定对象的意见判断、模糊态度等无法利用机器编码快速完成,就推荐人工编码,通过一定的机器辅助手段,相对提升编码效率 。
- 什么情况下选择AI编码?
AI编码适用于主观、客观类目题目,准确度可控,需要设置类目提示词,对类目选项下定义,需要消耗运算资源。可以和人工编码员的结果进行进度检验,编码结果可用在发表论文中。
有时候在实践中,一套编码表中会同时含有客观和主观型类目,也可以采用混合编码的方式完成数据处理。
实际上,(机器辅助)人工编码、机器编码,还有AI编码,都是大数据技术辅助、人工智能辅助内容分析法的一部分,适合不同的文本数据研究场景。接下来就详细介绍一下(机器辅助)人工编码、机器编码和AI编码的操作方式。
- (机器辅助)人工编码
顾名思义,由人工编码员阅读文本,并填答编码表,以此方式完成内容编码工作,适合分析主观性类目。传统内容分析法的操作方式正是如此,需要耗费大量的人力和时间成本,人工依赖性强,不适合大规模数据的分析任务。
作为长期围绕内容分析法展开工作的DiVoMiner研发团队深为理解人工编码的“苦”,因此在“纯”人工编码的基础上,开发出“机器辅助”的功能,用户可以对类目的选项设置配套关键字(词)条件(关于【类目设置】,相关信息可点这里回顾),设置好的字词可以在编码文本中高亮显示,并提供机器预选,减少编码员检阅文本时查找、匹配信息的功夫,即便是人工做编码,相比传统编码方式,效率也有很大程度的提升,准确度也大为提高。
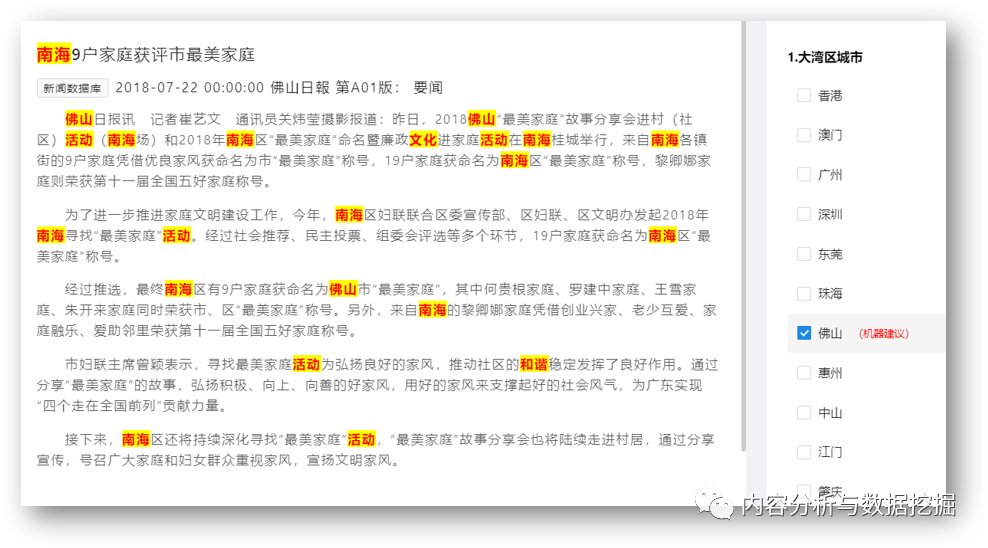
人工编码的数据准确性依赖于编码员的理解,因此为了保证数据的可靠性,需要在正式编码前进行编码员之间信度测试,关于信度测试的知识点,点这里回顾。
- 机器编码
大数据研究场景下,动用的数据样本动辄成千上万,甚至十万、百万、千万级别数据也不是稀罕事儿,人工编码在这种数据量的重压下捉襟见肘,难以为继。因此,在数据分析方面迫切需要计算机的协助。
在内容编码中,针对客观性类目,可以用文字总结出题目选项的语义范畴,则推荐利用计算机执行文本的分类工作,一键执行,依据用户自设的关键字(词)逻辑条件,自动完成编码表的填答,速度快,效率高,成千上万条数据可以在短时间内完成,而且多次重复执行结果完全一致,容易验证结果。
可以在对应数据库的【自动编码】或是【内容编码】下的【自动编码】中设置机器编码
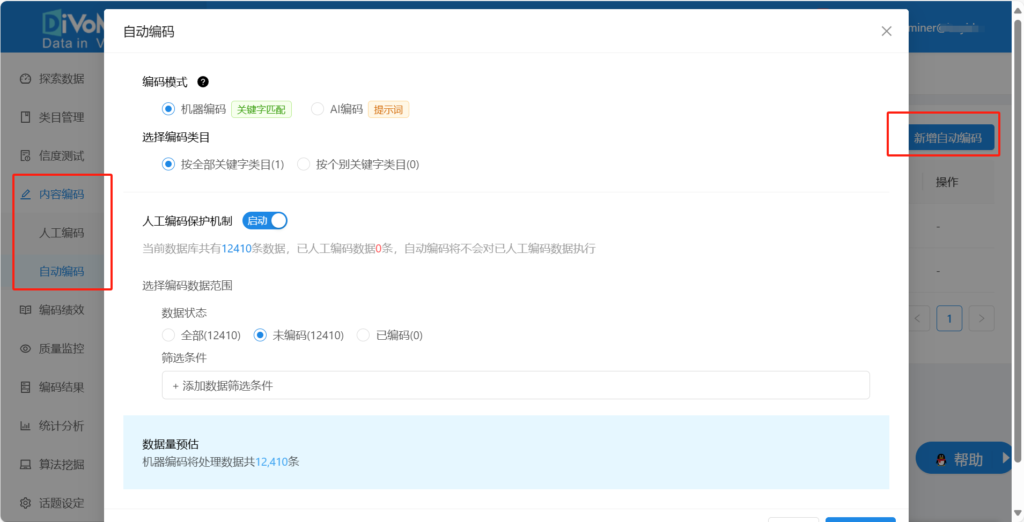
需要注意的是,机器编码并不是完全交由机器解决全部问题,机器编码结果高度依赖用户自设的选项关键词条件,“人”在其中发挥了极大的作用,人工介入的重要环节在于制定机器分类的标准,因此用户的研究能力、经验等容易影响编码结果的质量,并借此摆脱内容编码等机械性质的繁杂工作,让研究者的精力回归研究中。
提示:不论是机器编码,还是人工编码中的预选,依据都是由用户自设的类目中选项关键词决定的,因此,编码数据质量的高低,依然是取决于研究者的研究能力和思考成果,在一个研究里,有可能需要研究者反复调整设定和矫正结果,才能达到一个较佳的编码结果。
- AI编码
AI编码可快速对数据进行分类,相对人工编码,AI计算效率极高,编码结果也比较准确。AI编码需要先设置AI类目,与机器编码的运行机制不同,AI类目需要对题目、选项设置提示词,即是使用语言说明清楚编码的分类依据,AI编码的结果质量会与提示词的质量严格相关。
设置妥当后,运行AI编码的路径方式与机器编码一致,均是在数据库的【自动编码】或【内容编码】下的【自动编码】进行数据范围的设置和任务启动。
