
抽样(Sampling)是研究者常用的方法,从总体对象中抽取一部分,并通过对该部分进行研究,得出对总体的认识。
在研究实践中,抽样需要考虑两个问题,一是抽样规则,二是执行操作。依据研究需求,通常可选择对文本内容采用系统抽样或分层随机抽样,形成可供操作的编码样本库。具体选择何种抽样规则因研究场景而异。
而在执行操作层面, DiVoMiner®平台提供方便的抽样方法,具体操作可观看以下视频。
一共三步:建立抽样库,设置抽样规则,执行抽样,done!严格来说,需要用户操作的只有两步哦!具体方法是在【总览】界面,在需要进行抽样的数据库上点击【抽样】,弹框将显示抽样步骤。
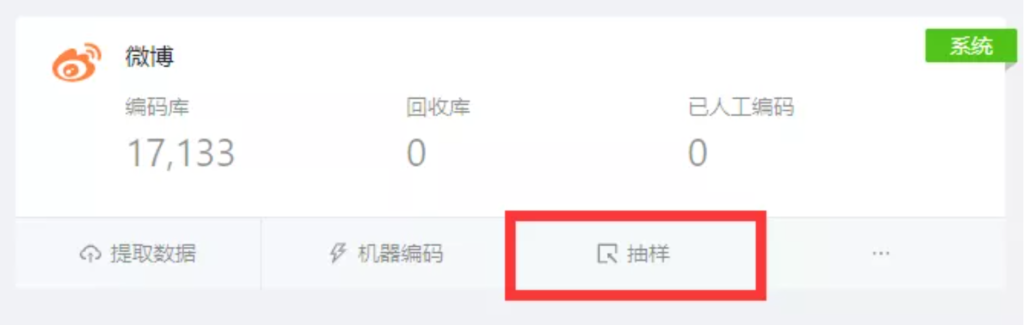
点击抽样后,如果没有已有的抽样库,即手动输入抽样库的名称,如“抽样库1”,新建一个抽样库,随后点击【下一步】。
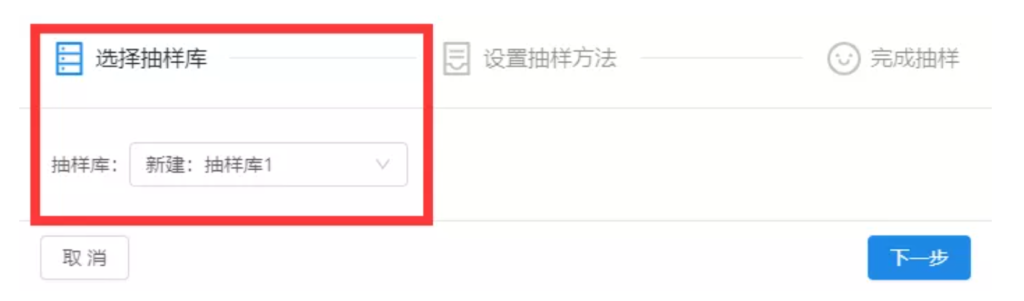
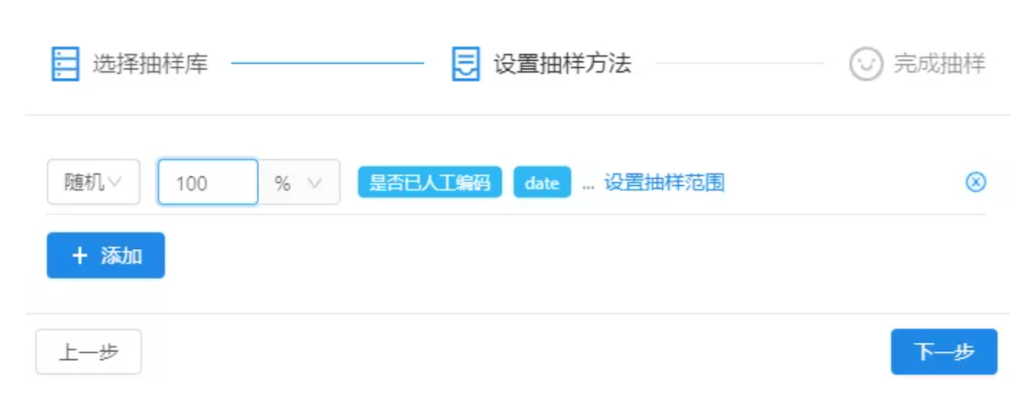
进入【设置抽样方法】设置抽样规则,如果进行简单随机抽样的话,那么我们只需要输入随机抽出的文本数据百分比、或者固定的微博数量,即可点击【下一步】。
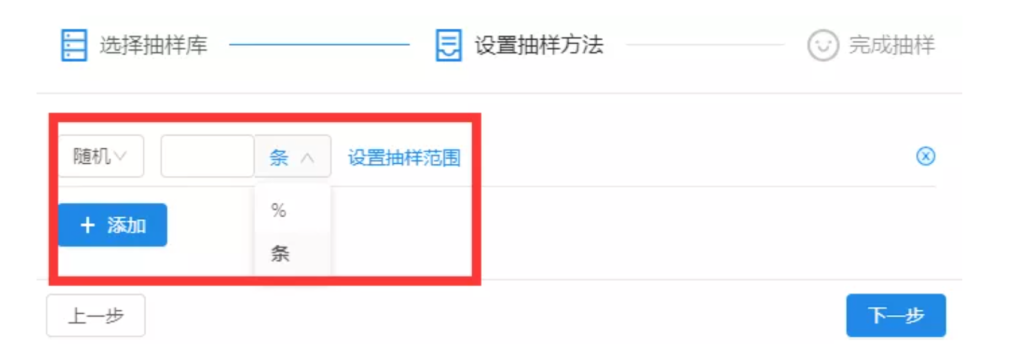
但是,在实际的文本分析中,在很多情况下,根据研究需求,会遇到较为复杂的抽样要求。比如希望优先抽出热门微博,进行人工分析。那么我们就可以点击【设置抽样范围】,对抽样规则进行个性化的制定。
在点击【设置抽样范围】后,调整抽样的条件和规则,既可以是满足下列“全部条件”(AND逻辑),也可以是“任意条件”(OR逻辑),点击“+”号或“-”号对条件进行增减。案例中,一口气设置了5个条件,使用“全部条件”,意思是,只有同时满足这5个条件的文本,才会被筛选出来作为进一步的分析样本。
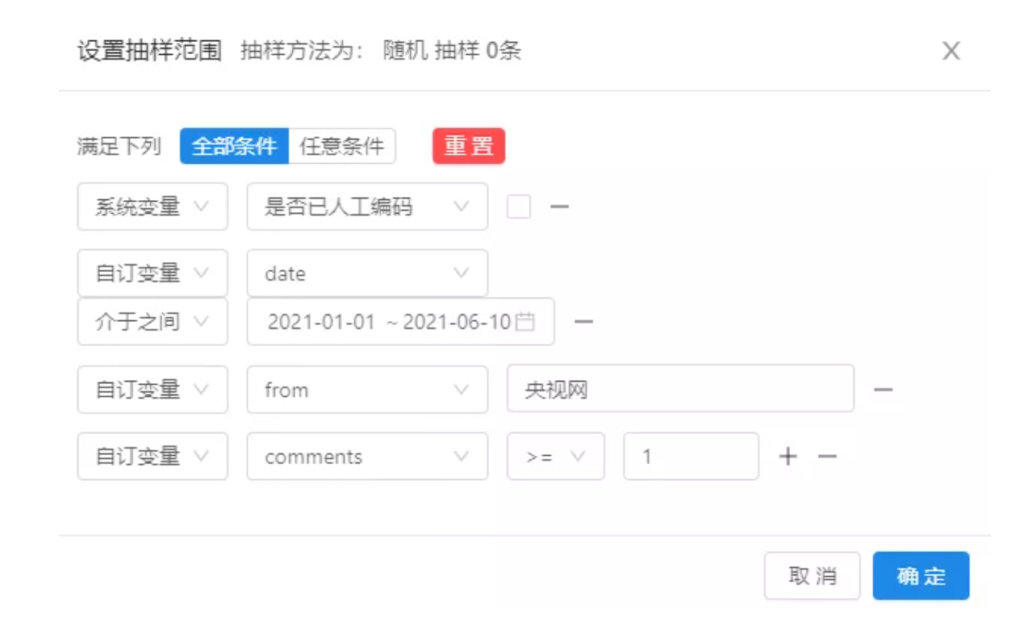
当然,这些条件都是可以自由选取的。回到【设置抽样方法】步骤,调整抽样字段和规则就可以了,比如根据点赞、评论、转发等条件进行升降序的抽样。
后续选择随机抽取100%、也就是符合上述所有条件的所有内容,然后点击【下一步】,即可开始抽样。 除了随机抽样,也可以按顺序或倒序选择抽样顺序。
接下来,只需要稍等片刻,抽样也就完成啦!是不是很方便、很高效呢!在DiVoMiner®平台上一次性完成多条件的复杂抽样,也是很容易的!
最后点击【查看数据】,就可以看到根据条件抽出来的符合条件数据了。提醒,在抽样后,会形成独立数据库,可以单独操作、多库并行,但是、抽样库是占用话题数据容量和文件容量的哟~记得合理规划话题使用情况。
